
Yi Ching, le livre des transformations (1)
Le Yi Jing, apparu il y a 3500 années, était un outil de divination utilisant des baguettes de bois. Au fil du temps, il est devenu la base d’une pensée philosophique et morale qui tentait de comprendre le monde et ses transformations. Celles-ci étaient représentées dans les hexagrammes qui figuraient le déroulement des événements selon des catégories dynamiques.
La création de 485 images a été nécessaire pour afficher les symboles du Yin Yang, les trigrammes et les hexagrammes. Ces images ont été générées avec du code Python écrit pour ce projet en utilisant OpenCV et Numpy. Ces images ont ensuite été montées dans Premiere Pro.
Les pièces musicales ont été générées à l’aide d’algorithmes d’intelligence artificielle :
• Amper Music de la société New-Yorkaise spécialisée en génération de musique;
• Dromify, un des outils de la suite de Magenta Studio qui provient de l’initiative de « Google Brain Team à partir de l’aria BWV 988 des Variations Goldberg de Jean-Sébastien Bach pour former un solo de batterie.
Yi Ching, le livre des transformations (2)
Yi Ching, le livre des transformations (3)
4500 images en IA
Ce projet est basé sur un algorithme d’intelligence artificielle qui utilise des images de référence (ici des images « texture » de Montréal) et qui attribue leurs caractéristiques « statistiques » au contenu d’autres images en vue de transformer ces dernières dans le style des images de référence. Des modèles de « style » sont ainsi produits, ce sont des réseaux de neurones artificiels créés à partir de plusieurs couches d’analyse des pixels, dix-neuf couches dans le cas du modèle VGG19 utilisé pour ce travail. Il y aura un traitement appliqué par image, avec un impact plus ou moins important selon le nombre d’itérations effectuées.

Mon salon
À partir de mappages en temps réel à l’aide d’une caméra stéréo Zed 2 de Stereolabs et de captures d’outils de visualisation de modèles 3D.
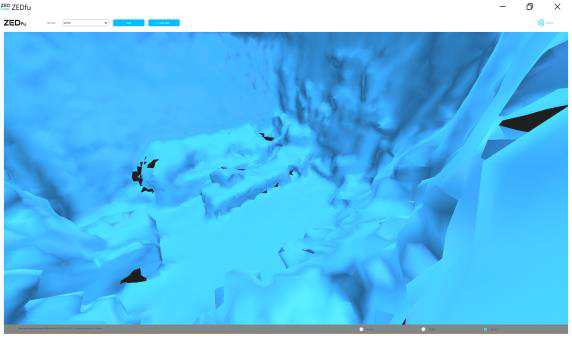
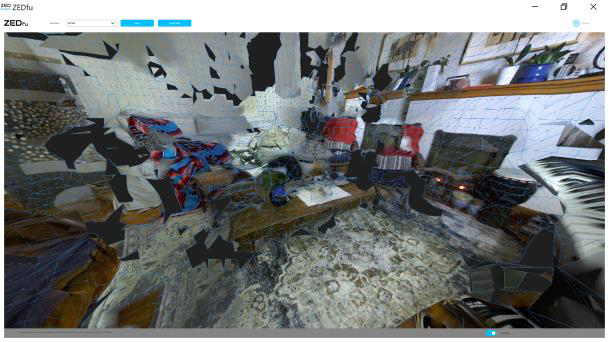
Je propose d’amener le spectateur à voir un espace imaginaire à travers les yeux d’une caméra stéréo et à recréer cet espace. Dans la première partie du vidéo, je surimpose les images de la réalité en 2D à celles d’un numérisation 3D de l’espace transposé dans les pixels en calculs de distance codés selon les couleurs. J’ajoute rapidement une autre couche visuelle où des arêtes de polygones sont générés pour reconstruire un espace 3D. Dans une deuxième partie, je suggère un état « nébuleux », se référant à une espèce de cosmogonie représentant un état de reconstruction des données acquises à partir de forces antagonistes, l’organisation et le désordre, pour recréer un petit monde, mon salon imaginaire, avec une apparence de réalité, mais une réalité altérée.
J’ai utilisé une caméra stéréo Zed 2 de Stereolabs que je pourrais qualifier de « semi-industrielle ». Elle s’utilise normalement avec une programmation en Python, mais de manière optimale en C++, souvent avec la bibliothèque OpenCV. Malheureusement, cette caméra n’est pas un produit mûr, il n’était pas possible d’utiliser les fonctionnalités d’enregistrement intégrées des résultats de mappage. Après avoir contacté le manufacturier, on me dit « this is a known problem caused by lost frames while saving the SVO and it will be soon fixed »… Je me suis retourné vers l’utilisation d’un exécutable de démonstration appelé ZEDfu (pour Zed fusion) qui présente trois fenêtres lors d’une capture des vecteurs 3D :
• L’image réelle;
• Le mappage des distances où la couleur des pixels montrent les distances plus ou moins grandes en transposant ces dernières selon une échelle de couleurs;
• Un matriçage vectoriel.
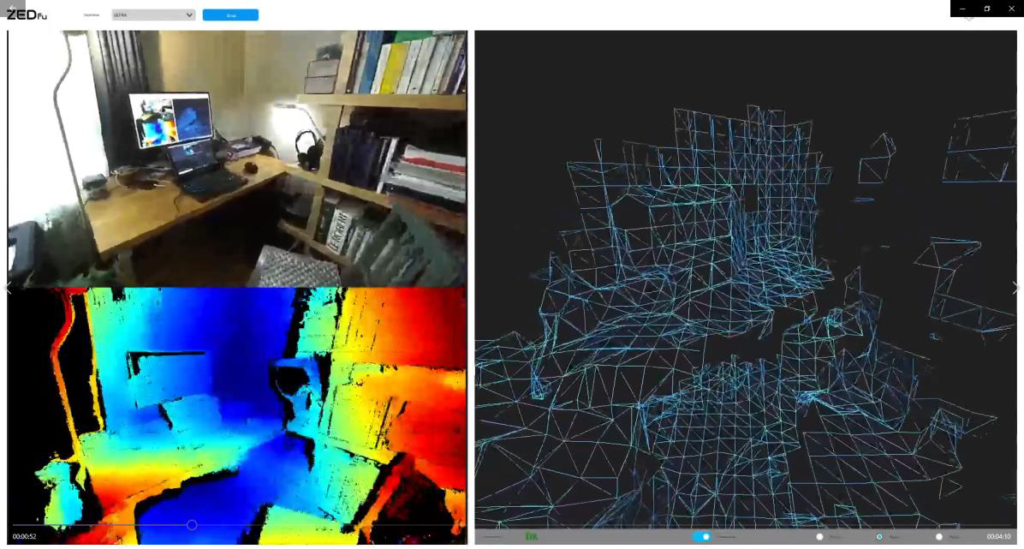
Avec logiciel OBS, j’ai capturé les images présentées en temps réel lors du mappage de la pièce avec le logiciel ZEDfu. Ce dernier logiciel compile aussi données accumulées lors du mappage pour produire des fichiers 3D (de type mesh.obj et mesh_raw.ply) à la fin de l’opération.
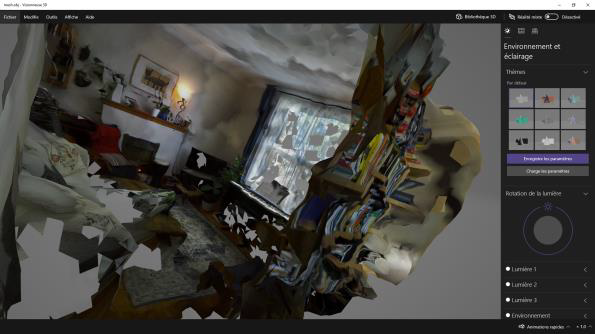
Dans les premières trente secondes du vidéo de mon étude, j’ai utilisé les captures des trois écrans réalisés pendant le mappage initial. Les trois captures ont été recadrées dans Adobe Premiere avec une transparence variable. Et pour la seconde partie du travail, les fichiers 3D mesh.obj et mesh_raw.ply ont été exploités avec la visionneuse inclue dans l’exécutable ZEDfu et la visionnneuse 3D de Microsoft afin d’enregistrer des vidéos d’animation (en rotation) des modèles 3D produit

À la manière de…
Expérimentation d’un réseau de neurones artificiels appliqué à 1800 images.
À partir d’une vidéo de pluie dans un caniveau, dans un transfert de style, à la manière de …
Là encore un projet s’appuie sur un algorithme d’intelligence artificielle basé sur le transfert de style. Les images de « contenu » à modifier proviennent d’un vidéo d’une minute d’un
caniveau lors d’une pluie. 1800 images ont été extraites de mon enregistrement à l’aide
de Adobe Premiere Pro 2021. D’une manière similaire, j’ai utilisé arbitrairement six images de peintures connues, ajoutées dans Premiere à raison de 10 secondes chacune et réexportées en 1800 images de « style ».
Comme mentionné précédemment, chaque image de contenu est traitée par l’algorithme avec une image de style. Pour effectuer une progression dans l’importance de la transformation des images, le nombre d’itérations croît et décroit au cours des dix secondes de chaque sous-séquence. Il y a une itération à la première seconde, pour croitre à cinquante itérations à cinq secondes et décroitre de plus en plus jusqu’à la dixième seconde. Ainsi de suite pour les six sous-séquences. Les images sont ensuite réintégrées dans Premiere.
Le choix est plus ou moins arbitraire, j’ai voulu utiliser des peintures connues qui se démarquent par leurs couleurs et leurs motifs (souvent déterminés par les coups de pinceau) :
• La Guernica de Pablo Picasso
• Composition VIII de Wassily Kandinsky
• Nénuphars et Pont japonais de Claude Monet
• Le Cri d’Edvar Munch
• La Nuit étoilée de Vincent van Gogh
• La Grande Vague de Kanagawa de Hokusai